This release includes fully tested support for the HyperSQL 2 DB
(formerly known as HSQLDB). That's the database that is embedded in
Open Office.
Monday, November 29, 2010
Thursday, November 18, 2010
Tuesday, November 16, 2010
Configuring database connectivity
User feedback has indicated that the DBConnectionInfo configuration element could use some documentation. DBConnectionInfo is particularly inscrutable, compared with other XML plan file elements, because it uses "constructor-arg"s that are referenced by index, instead of some type of descriptive property name. The user sees "<constructor-arg index="0"" and has no idea what that means. So I’ll detail the elements right here:
dbConnectionInfo.oracle.xml
<bean id="connectionInfo" class="org.diffkit.db.DKDBConnectionInfo"> <constructor-arg index="0" value="oracle" /><constructor-arg index="1" value="ORACLE" />
<constructor-arg index="2" value="XE" />
<constructor-arg index="3" value="10.0.1.11" />
<constructor-arg index="4" value="1521" />
<constructor-arg index="5" value="diffkit" />
<constructor-arg index="6" value="diffkit" />
</bean>
| Your name for this ConnectionInfo element. You can select an abitrary name, and it has no relationship with any real DB construct. This name is merely for presentation-- it will appear in the logs and some types of reports. | |
| The "Flavor" of connection. Can be any one of: H2, MYSQL, ORACLE, DB2, SQLSERVER, POSTGRES. These correspond to the constants in the Java enum org.diffkit.db.DKDBFlavor. | |
| The database name. This is what the vendor refers to as the database name. | |
| The hostname. Can also be an ip address. | |
| The port. | |
| The DB username you want to log in as. | |
| The DB password for username in 6. |
For Java programmers
DiffKit is configured using the "core" Spring framework. The above <bean></bean> XML element simply plugs the constructor-args into the longest Constructor of the org.diffkit.db.DKDBConnectionInfo class.
Saturday, November 13, 2010
DiffKit 0.8.1 released -- adds support for SQL Server
www.diffkit.org
Friday, November 12, 2010
How to regression test a database application (part 2)
This is part 2 of 2. In part 1 I characterize what is meant by "database application". I also quickly review some different types of regression testing, and then describe a hypothetical retail inventory example system which will serve as the subject of detailed discussion. In part 2, I explore the "final table" type of regression test in detail, and apply it to our retail inventory system. I conclude with an argument for why "final table" testing should always be included on your project.
The challenge
I’m the project manager for the AIR system, which was described in some detail in part 1. The system has been humming along in production for years, and now my developers are working on some significant functional changes to the system which are scheduled to be released shortly. My biggest concern is to not break something that is already working. For that I need some type of regression testing, but I"m unsure what the best regression strategy is. Some, but not all, of my system is already covered by Unit tests, and there are a couple of higher level functional tests that cover a slice. But there is no end-to-end fully integrated systems test.
In an ideal (fantasy) world, I would now instruct my developers to write regression tests, at all levels, covering every aspect of the system. They would write low level unit tests to test every DB function, DB stored procedure, and Java method. They would then write a higher level functional test for each slice. Finally, they would script, or automate, a highest level fully integrated end-to-end systems test.
Figures 1 & 2 (same as in part 1) diagram the system.
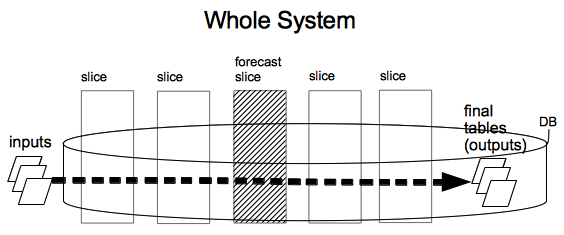
Figure 1: System
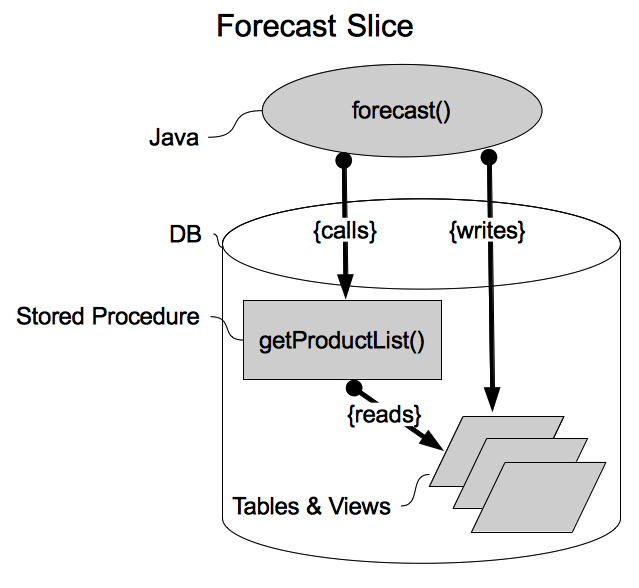
Figure 2: Forecast slice
Taking the Forecast slice as an example, if I want to competely cover this slice with Unit tests, my developers will need to write several for the getProductList() stored procedure. More than one Unit will be needed in order to exercises all of the possible boundary and error conditions. The test harness will need to somehow populate the underlying tables/views that are read by getProductList(). Just the Unit tests required to provide decent coverage for the getProductList() could take an entire day to write. Next, my Java developers need to provide Units to blanket the forecast() method. Since forecast() calls the getProductList() stored procedure, the forecast() Units will need to mock the stored procedure. Setting up mock stored procedures is itself an exacting and laborious endeavour. Again, providing comprehensive Unit coverage for just forecast() might pin down a Java developer for an entire day. Finally, all of the tables and views touched by this slice will also need their own Unit tests. These Unit tests will ensure that defaults, invariants, and constraints are always observed within the tables and views. If the views implement any business logic, that too must be covered by Unit testing.
All of the above Unit tests are data intensive. So in each case, the test writer must think long and hard about the possible range of data values that the subject function might be exposed to. The test writer will need to think about both expected values for each parameter or data set, and also possible values for each. After all, one of the goals of software testing is to ensure that the test subject continues to operate properly even in the face of unexpected or "flaky" data or paramters.
It’s clear that providing deep Unit test coverage for just the Forecast slice will entail significant effort. 3 developer days (1 for java, 1 for stored procedure, and 1 for tables/views) might be generous, but it’s not an unrealistic estimate, considering all of the different concerns involved. The Forecast slice is just one of many slices that constitute the whole system. In a complex enterprise system, and that includes most Big Enterprise systems, there will be hundreds or thousands of slices.
If my whole system has just 100 slices, it will take 300 developer days to achieve exquisite, comprehensive, rock-solid, Unit test coverage. Current software testing theory dictates that this is exactly the type of Unit testing you should have on a well run project. But as the manager of project AIR, I don’t have 300 developer days to write Unit tests. Purists will object that most of the Unit tests should already have been written before the current iteration, but on project AIR (as on many, if not most, Enterprise systems) they weren’t. That’s the fault of the previous project manager, but he has since moved on, so now it’s my problem. The theory dictates perfect Unit testing, but it’s hard to square that with time and resource constraints:
In theory there is no difference between theory and practice. In practice there is.
Jan L. A. van de Snepscheut
Alternatively, I can abandon the idea of blanket Unit test coverage. Instead, I could go to the other extreme and build just 1, fully integrated, end-to-end, systems test. One way to carry out this system test is to:
Final Table Test
- capture a complete set of inputs (files, tables, whatever) from the current production (pre-change) system.
- in an isolated, controlled, test environment, run those inputs through the complete current production (pre-change) system in order to produce outputs. I’ll call the outputs "final tables", because all of the outputs are captured in DB tables and those tables are at the end of a chain (or pipeline) of processing. The outputs from this run are labelled "expected".
- in an isolated, controlled, test environment, run those same inputs through the complete current in-development (post-change) system in order to produce outputs. Label those outputs "actual".
- compare the expected final tables with the actual final tables. They should match, except in the areas where there are intended functional changes that are meant to produce changes to the outputs.
Some benefits of this scheme are worth considering carefully. This is the ulimately "black box" test. The testers do not need to understand anything at all about the internals of the system. They only need to know which buttons to press in order to run the system, and which are the "final tables" they need to compare. So this is the type of test that an independent testing group (say QA) should be able to effect. Another interesting aspect of this approach is that of test data selection. The good part is that it relies on current production inputs, exactly the real-world data conditions that the application will experience in practice. Also, simply reusing production data alleviates the burden of the test team needing to carefully consider and synthesize test data. This could be a significant labor savings.
But perhaps the most important aspect of this type of testing is that it effectively tests the system at all levels. Put another way, the final table test can provide much of the test coverage that would be provided by the collection of Units, whereas Units cannot provide any coverage at the functional or system levels. As a result, even if you have a blanket of Unit tests, you still really do need to do some form of functional or systems test. That’s because the interfaces, or boundaries, between functions, modules, and slices have to be exercised. As an example, look at the Forecast Slice. Suppose I write individual Unit tests for getProductList(), forecast(), and the tables and views. I test the forecast() method by mocking up the getProductList(). That’s not sufficient to provide confidence that the slice is production ready. I need at least some functional tests that exercise forecast() making a real call against the getProductList() stored procedure. Otherwise, the Unit tests, in mocking the getProductList(), might make assumptions about the parameters, behaviour, or side effects, that are not consistent with the real (non-mock) getProductList(). Likewise, it’s not enough for me to simply write a functional test that just covers each slice. I need a still higher level test that exercises the interfaces between slices. So the bottom line is that, if you absolutely have to, you can live without Unit tests and rely exclusively on a single, integrated, systems test (final table test). But the converse is not true. Even if you have superbe Unit test coverage, you will still need to perform some integrated systems testing.
Of course, the final table test is hardly bulletproof. Probably the biggest problem with this test is that it is a relative test, wherease the Units are absolute. By that I mean the final table test only tells you that the changed system behaves the same as the reference (current production) system that you compare it against. If the current production system is producing incorrect results, and your changed system passes the final table test, then your changed system will also be producing incorrect results in exactly the same fashion. The Unit tests, on the other hand, are measured against absolute expectations, not relative ones. So Unit tests are better grounded. Also, the final table test only tests aspects of the system that will be exercised by the current production data inputs. It’s possible that there are bugs lurking in the newly developed (changed) system, but that the bugs are not triggered by the current production data inputs. But the production data could change at any time in a way that would then trigger the bug, but in production. One more material drawback of the final table test is that it can only be carried out late in the Software Development Cycle, whereas Unit tests are able to uncover problems very early on in the cycle. That’s important because it’s generally, though not always, more expensive to correct bugs late in the cycle than early in the cycle.
| Units | Final Table | |
|---|---|---|
bug detection | early | late |
level | lowest, function | highest, system |
test type | white box | black box |
coverage | isolated | comprehensive |
results type | absolute | relative |
effort | large | small |
impl. expertise | programming | operations |
data | synthetic | production |
The key to deriving maximum benefit from the final table test is that the final tables comparison be carried out at the actual field value level. That is, every row+column in the expected final tables must be compared with its corresponding row+column in the actual final tables. Remarkably, very few shops that utilize a fully integrated systems test actually carry out these detailed comparisons. Instead, they rely on gross (summary level) comparisons, and visual inspection of the resulting data sets. That is completely inadequate.Many bugs can, and do, elude gross and visual comparisons.
The conclusion is that you must perform some type of fully integrated systems test, and a very powerful and cost effective option for this is the "final table test". Of course, high quality projects will also have low-level Unit tests and mid-level functional tests. However, if you are in a bind, constrained by very limited developer and testing resources, I would recommend that the first and foremost test you should carry out is the final table test.
Wednesday, November 10, 2010
How to regression test a database application (part 1)
This is part 1 of 2. In part 1 I characterize what is meant by "database application". I also quickly review some different types of regression testing, and then describe a hypothetical retail inventory example system which will serve as the subject of detailed discussion. In part 2, I explore the "final table" type of regression test in detail, and apply it to our retail inventory system. I conclude with an argument for why "final table" testing should always be included on your project.
Database Applications
Here, a database application means a software system that uses an RDBMS as its primary persistence mechanism. In other words, a database application is built on top of, and around, a relational database. The application logic might be implemented within the database itself, in the form of stored procedures and other database objects, or it might be implemented outside the database in a general purpose programming language such as Java or .NET. It’s quite common that Big Enterprise sytems are implemented using a layered mixture of different programming technologies. Another characteristic of database applications is that the application data, in the database, is the primary window through which the application teams (developers and admins) monitor the health of the system and evaluate the correctness of the results.
Regression testing is a well established technique to help ensure the quality of software systems. The intent of regression testing is to assure that a change, such as a bugfix, did not introduce new bugs. At its most basic level a regression test reruns a function that used to work and verifies that it still produces the same results. The basic elements of a regression test are:
- a function to test. The function must have identifiable inputs and outputs. Function here is meant in the broadest possible sense. It could represent a database stored procedure, a Java method, an RDBMS View, or a high level shell script job that choreographs other jobs. Any software artifact that is callable or invocable.
- a predetermined, capturable (i.e. saveable), input data.
- a predetermined, capturable, expected output data for the above input data.
- an actual output, which results from applying the latest revision of the function to the input data above.
- a means for comparing the expected output with the actual output to determine if they are the same or if they are different in a way that is expected.
Regression testing can be applied at many different levels. Applied at the lowest, most primitive, level it is called a "Unit Test". Unit testing applies a laser focus on one low level functional unit. Unit tests are very popular amongst the general purpose programming language communities, such as Java and Python. Testing above the Unit level is generally referred to as functional testing. Again, functional testing can ocurr at different levels. It can test software modules that compose the lowest level operational units into higher level functions. Here, I call a high-level functional module that implements one complete business function a slice. At the top of the testing hierarchy is the system test. The system test exercises the fully integrated, end-to-end, system at the highest possible level. It touches all functions and modules. This usually corresponds to the same level at which the users experience the system.
A Concrete Database Application Example
For the sake of better illustrating the concepts and techniques in this article, I’ll invent a hypothetical database application called the "Automated Inventory Replenishment" system — AIR. The AIR system is maintained by a midsized enterprise that is in the retail sales business. Every day, the business sells a portion of its inventory (stock) and must decide how to restock the store shelves. The AIR system is highly streamlined and simplified, in order to allow focus on just the salient points. The enterprise performs the restocking only once per day, after all of the stores have closed. As a result, AIR is run once per day, well after the close of business. AIR is run in a batch mode-- a single invocation of the system performs a complete, daily, restocking cycle.
Figure 1. shows the complete AIR system.
Figure 1: System
There are many different functional modules, or slices, needed to complete the entire cycle. The inputs are: the current level of inventory for each product, pricing and availability for all products we might want to purchase, and a listing of all available unoccupied shelf space. AIR must determine which product orders to place in order to fill all of the unoccupied shelf space. So the outputs are simply a list of product orders (SKUs and quantities). The outputs are stored in a single table in the database, which is referred to as the "final table" because it is the end (terminal) of a chain of tables used during processing. One of the slices, the "Forecast Slice", is exploded in detail in Figure 2:
Figure 2: Forecast slice
The forecast slice is responsible for guessing how much of each product will be needed (or wanted) for the next business week. These forecast results are one of many importantant inputs to the final ordering function. The final ordering determination has to include not just forecast information, but also price and availability. The forecast slice is implemented as a Java function (method), a DB stored procedure, and a collection of tables and views. Java was chosen for the detailed forecast business logic, because the calculations and flow control are very complicated and better suited for a general purpose programming language than for an embedded database procedural language (e.g. pl/sql). The Java method calls the stored procedure getProductList(), which returns a complete list of all products that we might want to forecast for. The Java forecast method writes all of the forecasts (results) to a table.
Suppose I’m the project manager for the AIR system, and it has been in production for several years. Let’s also suppose that new functional and operational requirements are fed to team AIR on a regular basis. My team is working on changing the system in order to provide new business functionality. But before I can release these changes into the production environment, I have to be confident that we are not breaking something that already works. Let’s suppose that the current level of operational integrity of AIR is fair; then, even minor bugs introduced as a result of change could very well cause noticeable degradation of operational integrity for AIR, and appreciable degradation of career prospects for staff. Clearly, some form of regression testing is called for. But it’s not at all clear which tests will give the highest level of confidence for the least amount of work. Say that some of the slices are covered by both unit and higher level functional regression tests. But, as in most real-world custom-built enterprise applications, most slices are not covered by rock-solid automated regression. For some slices, there are no regression tests at all. For others, there are some unit and functional tests that, history has shown, catch some, but not all, of the bugs that typically creep in as a result of system change.
As project manager, I now have to decide what mix of regression tests will provide the biggest bang-for-the-buck. In part 2 I dive into the details of the costs and benefits associated with the different types of regression tests.
Thursday, November 4, 2010
Big Hairy Batch (BHB)
Periodic batch processing is a common activity in Big Enterprise. "Batch", as it is usually referred to, is now recognized as a distinct enterprise specialty deserving its own tools, techniques and designs. In fact, Spring has introduced within the last few years a framework geared specifically for the unique characteristics of batch: Spring Batch.
The most common characteristics of batch are:
- They’re periodic. Daily or monthly periods are the most common, because these periods correspond to important business cycles, such as the daily portfolio and instrument repricing that many financial firms live by, or the monthly accounting and balance sheet reconciliation that most regulated companies are required to provide for the public equity markets.
- They are "automatic" (or at least they are supposed to be). That means they run on a timer (according to their period) rather than in response to user generated events.
- They typically import several different sources of data, transform those inputs according to a number of pipelined steps, and produce one or more outputs that are usually stored (at least temporarily) in an RDBMS.
- The outputs can be consumed by the same system that generated them, by external downstream systems, or both.
Batches come in many different shapes and sizes. I believe that the most challenging kind of batch, from an operational and test perspective, is what I call the Big Hairy Batch (BHB). The BHB layers the following traits on top of the standard batch:
- The inputs come from tens, hundreds, or thousand of different sources, in many different formats.
- The inputs are heterogeneous; many different kinds of data are sourced, even if one of those kinds is principal.
- The inputs do not arrive in the desired format. Extensive "reformatting" is necessary to put the inputs into a shape that is amenable to further processing.
- The inputs are not all expressed according to a common world view. For instance, the same underlying reference value or entity may be referred to differently in different sources. So an extensive "normalization" of the data from different sources is necessary before the different sources can be combined in a single view.
- The data volumes are large. The principal entity may have tens of millions of instances (rows) and hundreds of attributes (columns).
- The data is very messy. There are lots of breaks and inconsistencies and duplications, etc.
- The processing necessary to tranform the inputs to outputs is, conceptually, hugely complicated and complex. Some data must travel through multiple pipelines, and each pipeline can have multiple steps. Some pipelines have dependencies on other pipelines. Some pipelines have dependencies on external callouts (to outside systems). The specific logical functions within a pipeline step might involve very sophisticated or heavy computations.
- The processing implementations are complicated and difficult to maintain. Usually, the logic and procedures needed to carry out the batch are implemented in a rich melange of diverse technologies. There must be some type of high-level choreography system (programming in the large) to script or drive the entire process; a prominent example would be CA AutoSys. Business logic is spread across the entire application stack: some is in stored procedures and views in a database, some is in middleware in general purpose programming languages (java, c++, python), and some of it is in front-end oriented modules such as MS .NET. Invariably, at the center of the entire batch is a very complex, very overworked Very Large Database (VLDB).
- The BHB system has very few, if any, automated systematic regression tests in place.
- BHB has a daily period. Fresh BHB outputs are needed every day in order to carry out business as usual. Each day, the business needs the outputs as close as possible to the beginning of the workday, in order to meet all of their daily business obligations. BHB starts processing as early in the morning as possible, as soon as inputs become available, and struggles to deliver outputs by the beginning of the business day. Any delays due to the time required to process massive volumes, or due to delays from upstream systems, or due to operational failures, will ripple through to the business for the entire day.
- The BHB team is under pressure to deliver continuous, significant, changes to how the BHB works. These pressures originate from many different sources: changes to business strategy, changes to the systems environment, changes to upstream or downstream systems, etc.
In this environment, the BHB team really has their work cut out for them in trying to maintain the operational integrity of the system while carrying out requested changes. The biggest risk is that changing something will break something that used to work. What are the most productive techniques and tools to guard against this possibility? That’s the subject for a future post.
Tuesday, November 2, 2010
What is enterprise?
A large segment of the IT industry focuses on the enterprise: enterprise software, enterprise solutions, enterprise architecture, etc. But what is "enterprise"? According to Wikipedia:
There is no single, widely accepted list of enterprise software characteristics, …
In that case, I’ll take a shot at it ;). However, my list of enterprise traits is not an attempt at a universal definition. Instead, I’m relating my experiences in "Big Enterprise", based on tours in half a dozen fortune 500 companies.
- Big Enterprise has Big Data: many databases, many database vendor products, many many tables, huge volume, and heterogeneous types of data.
- Big Enterprise has Messy Data. A huge number of different actors have operated on the data continuously over a decade or more. Under those circumstances, it’s impossible to keep your data perfectly rationalized. Instead, there tend to be a lot of inconsistencies, breaks, gaps, reconciliation failures, and dupcliations in the data. Frequently, it’s not possible to impose clean relational constraints.
- Big Enterprise has messy data processes. It has accumulated many different processes to originate, deliver, and transform its data. It has connected these processes together using the cement of different programming/scripting languages and vendor tools. It has globalized, outsourced, insourced, off-shored and re-shored. It has built layer upon layer of intertwingled processing logic in a kind of palimpsest.
- Big Enterprise has incomprehensible data and processes. Realistically, complex software and data is prohibitively expensive to document properly. Creating documentation that accurately and fully describes a complex system, to all levels of detail, in a manner that naive readers would be able to make sense of, is much more difficult than the enterprise pretends. And once you consider the fact that the software and data is constantly evolving, it’s effectively (within normal enterprise IT budgets) impossible. Instead, the knowledge of the system is captured in the brains of the staff. But staff leaves, and so some knowledge about the systems is lost. It can be (and sometimes is) reacquired, but only at a substantial cost and on a as-needed basis.
- Big enterprise is organizationally rigid and compartmentalized. In the big enterprise, there is a lot of management hierarchy. Also, big enterprise formally separates roles and responsibilities in a way that doesn’t always align with the needs of the IT staff. For instance, most big enterprises will formally split the functions of development (changeing the IT artifacts) from the functions associated with validating that the changes are correct (usually referred to as QA). Often, the QA group does not have the skills necessary to carry out the sophisticated validations that are necessary for a rock solid quality assurance against a very complex system, especially if the system covers a domain that requires specialized business expertise to understand. It’s not uncommon that the development teams are disinclined to work on the QA aspect of the system, since it is not formally part of their job and thus amounts to unpaid work. Project managers are usually well aware of the shortcomings with this arrangement but lack the political or corporate power to overstep the existing managerial boundaries.
- Big enterprise is a stressful, chaotic, operating environment for the people who are tasked with maintaining the data and the processes that operate on it. The forces of Big Data, Messy Data, messy data processes, incomprehensibility, staff turnover, bureaucracy, and competitive pressures on the corporation conspire to keep the staff under-the-gun.
This environment is going to dictate which tools and processes are most successful. As the project managers, team leads, and architects in the Big Enterprise confront the challenges above, they must select the tools and technologies that will give them the biggest return-on-investment within their planning horizon. A normal planning horizon for a Big Enterprise project manager or team lead is a couple of weeks to a couple of months. Anything beyond that is "strategic" and highly risky (and therefore implausible). A tool or technique that requires substantial operational or cultural change in the enterprise IT environment, rather than adapting to it, is unlikely to succeed. In other words, agile is as agile does.
Subscribe to:
Posts (Atom)