This is part 1 of 2. In part 1 I characterize what is meant by "database application". I also quickly review some different types of regression testing, and then describe a hypothetical retail inventory example system which will serve as the subject of detailed discussion. In part 2, I explore the "final table" type of regression test in detail, and apply it to our retail inventory system. I conclude with an argument for why "final table" testing should always be included on your project.
Database Applications
Here, a database application means a software system that uses an RDBMS as its primary persistence mechanism. In other words, a database application is built on top of, and around, a relational database. The application logic might be implemented within the database itself, in the form of stored procedures and other database objects, or it might be implemented outside the database in a general purpose programming language such as Java or .NET. It’s quite common that Big Enterprise sytems are implemented using a layered mixture of different programming technologies. Another characteristic of database applications is that the application data, in the database, is the primary window through which the application teams (developers and admins) monitor the health of the system and evaluate the correctness of the results.
Regression testing is a well established technique to help ensure the quality of software systems. The intent of regression testing is to assure that a change, such as a bugfix, did not introduce new bugs. At its most basic level a regression test reruns a function that used to work and verifies that it still produces the same results. The basic elements of a regression test are:
- a function to test. The function must have identifiable inputs and outputs. Function here is meant in the broadest possible sense. It could represent a database stored procedure, a Java method, an RDBMS View, or a high level shell script job that choreographs other jobs. Any software artifact that is callable or invocable.
- a predetermined, capturable (i.e. saveable), input data.
- a predetermined, capturable, expected output data for the above input data.
- an actual output, which results from applying the latest revision of the function to the input data above.
- a means for comparing the expected output with the actual output to determine if they are the same or if they are different in a way that is expected.
Regression testing can be applied at many different levels. Applied at the lowest, most primitive, level it is called a "Unit Test". Unit testing applies a laser focus on one low level functional unit. Unit tests are very popular amongst the general purpose programming language communities, such as Java and Python. Testing above the Unit level is generally referred to as functional testing. Again, functional testing can ocurr at different levels. It can test software modules that compose the lowest level operational units into higher level functions. Here, I call a high-level functional module that implements one complete business function a slice. At the top of the testing hierarchy is the system test. The system test exercises the fully integrated, end-to-end, system at the highest possible level. It touches all functions and modules. This usually corresponds to the same level at which the users experience the system.
A Concrete Database Application Example
For the sake of better illustrating the concepts and techniques in this article, I’ll invent a hypothetical database application called the "Automated Inventory Replenishment" system — AIR. The AIR system is maintained by a midsized enterprise that is in the retail sales business. Every day, the business sells a portion of its inventory (stock) and must decide how to restock the store shelves. The AIR system is highly streamlined and simplified, in order to allow focus on just the salient points. The enterprise performs the restocking only once per day, after all of the stores have closed. As a result, AIR is run once per day, well after the close of business. AIR is run in a batch mode-- a single invocation of the system performs a complete, daily, restocking cycle.
Figure 1. shows the complete AIR system.
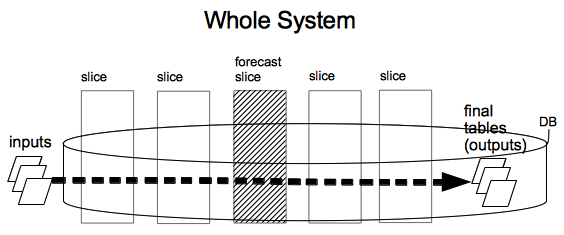
Figure 1: System
There are many different functional modules, or slices, needed to complete the entire cycle. The inputs are: the current level of inventory for each product, pricing and availability for all products we might want to purchase, and a listing of all available unoccupied shelf space. AIR must determine which product orders to place in order to fill all of the unoccupied shelf space. So the outputs are simply a list of product orders (SKUs and quantities). The outputs are stored in a single table in the database, which is referred to as the "final table" because it is the end (terminal) of a chain of tables used during processing. One of the slices, the "Forecast Slice", is exploded in detail in Figure 2:
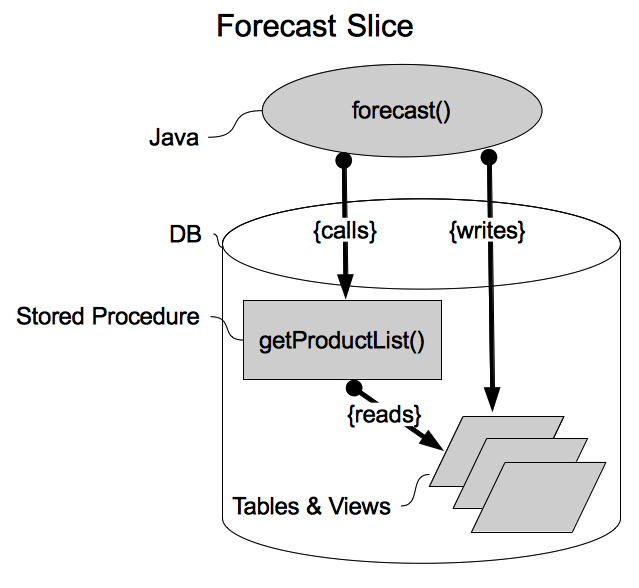
Figure 2: Forecast slice
The forecast slice is responsible for guessing how much of each product will be needed (or wanted) for the next business week. These forecast results are one of many importantant inputs to the final ordering function. The final ordering determination has to include not just forecast information, but also price and availability. The forecast slice is implemented as a Java function (method), a DB stored procedure, and a collection of tables and views. Java was chosen for the detailed forecast business logic, because the calculations and flow control are very complicated and better suited for a general purpose programming language than for an embedded database procedural language (e.g. pl/sql). The Java method calls the stored procedure getProductList(), which returns a complete list of all products that we might want to forecast for. The Java forecast method writes all of the forecasts (results) to a table.
Suppose I’m the project manager for the AIR system, and it has been in production for several years. Let’s also suppose that new functional and operational requirements are fed to team AIR on a regular basis. My team is working on changing the system in order to provide new business functionality. But before I can release these changes into the production environment, I have to be confident that we are not breaking something that already works. Let’s suppose that the current level of operational integrity of AIR is fair; then, even minor bugs introduced as a result of change could very well cause noticeable degradation of operational integrity for AIR, and appreciable degradation of career prospects for staff. Clearly, some form of regression testing is called for. But it’s not at all clear which tests will give the highest level of confidence for the least amount of work. Say that some of the slices are covered by both unit and higher level functional regression tests. But, as in most real-world custom-built enterprise applications, most slices are not covered by rock-solid automated regression. For some slices, there are no regression tests at all. For others, there are some unit and functional tests that, history has shown, catch some, but not all, of the bugs that typically creep in as a result of system change.
As project manager, I now have to decide what mix of regression tests will provide the biggest bang-for-the-buck. In part 2 I dive into the details of the costs and benefits associated with the different types of regression tests.
It is also the same with Hadoop testing through various models. We utilize ping signals and connection packet traffic for generic network management software before testing out the main enterprise software.
ReplyDeleteThat's a good read. Thanks. Shared an article on database regression testing - http://bit.ly/1qDOy8f. Might be a good further read.
ReplyDeleteThanks for your informative article on UFT automation testing tool. Your post helped me to understand the features and functionality of QTP automation testing tool. QTP training
ReplyDeleteTechnology place a vital part in humans ecosystem. So in order to survive one must be up to date. Thanks for sharing this information in here. Keep blogging article like this. I have bookmarked this page for future reference.
ReplyDeleteHadoop Training Chennai | Big Data Training
| JAVA training in Chennai
Your blog is awesome..You have clearly explained about it ...Its very useful for me to know about new things..Keep on blogging..
ReplyDeleteHadoop training in chennai
Database is explained very nicely...QTP Training in Chennai | QTP Training Institute in Chennai | QTP Course in Chennai
ReplyDeleteWhat a great think really informative post thanks for useful sharing Gorilla Online Marketing
ReplyDeletecoach outlet
ReplyDeleteconverse shoes
ysl outlet
birkenstock sandals
uggs
the north face outlet
oakley vault sunglasses
rolex watches
michael kors handbags
longchamp bags
20161124caiyan
Well Said, you have furnished the right information that will be useful to anyone at all time. Thanks for sharing your Ideas.
ReplyDeletePHP Training in Chennai | PHP course in Chennai
true religion outlet
ReplyDeletecoach outlet
louboutin pas cher
true religion outlet store
ralph lauren sale clearance
michael kors outlet clearance
ugg australia
adidas super color
canada goose jackets
ralph lauren outlet
20170109
toms shoes
ReplyDeletenike air max
mcm outlet
parker pens
new balance sneakers
replica rolex watches
nike free running shoes
michael kors handbags
michael kors handbags
christian louboutin shoes
2017.3.21xukaimin
The blog gave me idea to perform regression test on database My sincere Thanks for sharing this post and please continue to share this post
ReplyDeleteSoftware Testing Training in Chennai
Nice information!!! I prefer Loadrunner automation testing tool to validate the performance of software application/system under actual load.
ReplyDeletesoftwaretesting training in chennai
our content is awesome . You have done a great job and its very useful for me . I appreciate your effort and I hope that you will get more positive comments from the web users.. Want to learn software testing reach us at Software Testing Training in Chennai | Selenium Training in Chennai
ReplyDeleteIt has been our experience that, defending on the size of the system, it is sometimes necessary to dial this number back to eliminate overloading the database.create mysql dashboard
ReplyDeleteWonderful post. I am learning so many things from your blog.keep posting
ReplyDeleteAbinitio Online Training
Hadoop Online Training
Cognos Online Training
This information is very useful. thank you for sharing. and I will also share information about health through the website
ReplyDeleteCara Mengobati Cacingan pada Anak
Obat Benjolan di Belakang Telinga
Cara Mengobati ruam Kulit pada Bayi
Cara Cepat Mengobati Amandel
Obat Luka Berair yang Tak Kunjung Sembuh
Pengobatan efektif Menghilangkan Benjolan di Payudara
20180710 JUNDA
ReplyDeleterockets jerseys
canada goose
kobe 9
christian louboutin shoes
michael kors outlet online
nike blazer pas cher
clippers jerseys
nike revolution
jordan shoes
prada handbags
Great blog! Thanks for giving such valuable information, this is unique one. Really admired.
ReplyDeleteQTP Training in Chennai
Great Post Thanks for sharing
ReplyDeleteDevOps Certification in Chennai
Salesforce Training in Chennai
Microsoft Azure Training in Chennai
ReplyDeleteVery innovative article! I have a lot of knowledge from your incredible post and this content was very applicable to gain myself. Thank you...!
Linux Training in Chennai
Linux Course in Chennai
Social Media Marketing Courses in Chennai
Pega Training in Chennai
Oracle Training in Chennai
Oracle DBA Training in Chennai
Tableau Training in Chennai
Unix Training in Chennai
Excel Training in Chennai
Linux Training Fees in Chennai
This comment has been removed by the author.
ReplyDeleteGreat Post Thanks for sharing
ReplyDeleteORACLE TRAINING IN CHENNAI
super...
ReplyDeleteDATA SCIENCE TRAINING IN CHENNAI
ReplyDeleteINSTALL RPMS DIRECTORY
INTERVIEW QUESTIONS
APTITUDE
INTERVIEW QUESTIONS
VERBAL REASONING
FLIPKART WALLET HACK
TOOL
INTERVIEW QUESTIONS CHEMISTRY
TUTORIALS C
PROGRAMMING
BEST APACHE PIG TUTORIALS
TOP APTITUDE INTERVIEW
QUESTIONS
APACHE PIG TOKENIZE FUNCTION
RESUME FORMAT FOR RETIRED
GOVERNMENT OFFICER
share many post.
ReplyDeletejs max int
c++ program to print pyramid using *
why do you consider yourself suitable for this position
hack whatsapp ethical hacking
databricks interview questions
paramatrix aptitude questions and answers
which is the closest approximation to the product 0.3333
a watch was sold at a loss of 10
ip spoofing tutorial
advantages of packages in java
ReplyDeleteشركة تنظيف في الكويت شركة تنظيف بالكويت
فني صحي فني صحي
سباك الكويت سباك صحي بالكويت
شركة غسيل سجاد الكويت شركة مصبغة غسيل تنظيف سجاد الكويت
فني كهربائي منازل الكويت معلم فني كهربائي منازل في الكويت
nyc..blog
ReplyDeletecoronavirus update
inplant training in chennai
inplant training
inplant training in chennai for cse
inplant training in chennai for ece
inplant training in chennai for eee
inplant training in chennai for mechanical
internship in chennai
online internships
very nyc..
ReplyDeletecoronavirus update
inplant training in chennai
inplant training
inplant training in chennai for cse
inplant training in chennai for ece
inplant training in chennai for eee
inplant training in chennai for mechanical
internship in chennai
online internships
Your blog is absolutely fantastic and great android apps development tutorial for beginners. Good work.
ReplyDeleteOracle Training | Online Course | Certification in chennai | Oracle Training | Online Course | Certification in bangalore | Oracle Training | Online Course | Certification in hyderabad | Oracle Training | Online Course | Certification in pune | Oracle Training | Online Course | Certification in coimbatore
Wonderful sharing..thanks a lot for writing this article.
ReplyDeleteOracle Training | Online Course | Certification in chennai | Oracle Training | Online Course | Certification in bangalore | Oracle Training | Online Course | Certification in hyderabad | Oracle Training | Online Course | Certification in pune | Oracle Training | Online Course | Certification in coimbatore
A clean space is important for every organization because it creates a positive impression on customers or guests that come in. It’s also important for employees because it shows that the company cares about them and their well-being. For partners, it sends an invitation to use the organization’s products or services. This is why commercial cleaning company Dallas TX becomes necessary on every level.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteHey there, I’m William, a passionate web developer residing in the sunny coastal city of San Diego, California. With a knack for both coding and creativity, I thrive in the dynamic world of web development and design.
ReplyDeleteCricut has been a revolutionary machine in the DIY industry for many years. It’s easy to set up and use with its premium design software, Design Space. Get one machine and set it up via Cricut.com/setup.
ReplyDeleteเว็บทีเด็ดบอล ควรพิจารณาความน่าเชื่อถือ โดยตรวจสอบข้อมูลผ่าน บ้านผลบอล และเปรียบเทียบกับ เว็บวิเคราะห์บอล อื่นๆ รวมถึงดูความแม่นยำของ ทีเด็ดบอลวันนี้ และข้อมูลจาก ทีเด็ดบอลแม่นๆวันนี้ บ้านผลบอล
ReplyDeleteGreat introduction to regression testing for database applications. Clear approach on ensuring data integrity and stability before changes are deployed. retirement planning advice
ReplyDelete